The doctoral work for Hasan Asy’ari Arief concludes that deep learning-based techniques can improve and speed up the creation of high accuracy annotation labels for large point cloud data with a much lower price tag.
The Ph.D. thesis is devoted to the remote sensing and computer vision community.
It has been known that high accuracy annotation labels can improve the quality of the automatic perception system significantly. A system that is important for ensuring safety and reliability especially for autonomous vehicle application, augmented reality, remote sensing, and in the domain of robotics. However, providing those high accuracy labels is not trivial especially in the point cloud domain. Researchers have been trying to balance between cost and accuracy on providing these annotation labels, for example by combining simulation and real-world data to a reasonable degree, therefore the combined data can still be used to represent the real world. Moreover, for a case-specific scenario, the need to have high-quality annotation labels become more demanding while the effort on providing them increasingly costly.
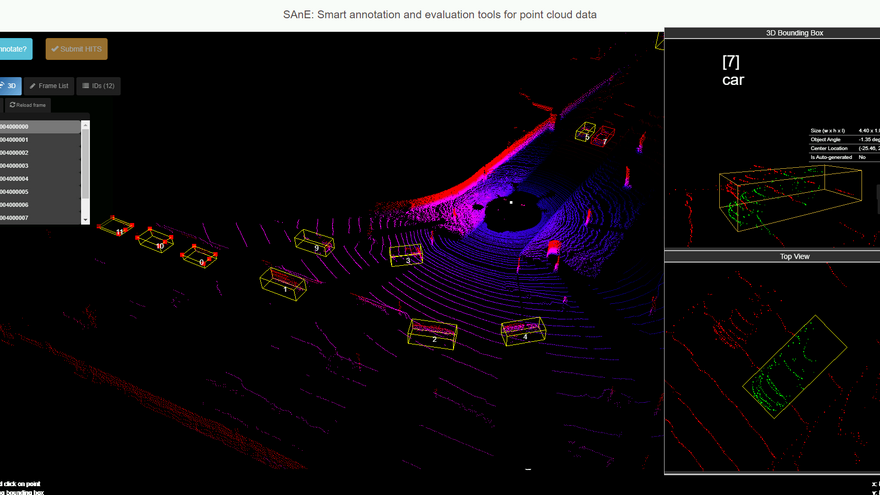
Our work bridges these issues by providing high accuracy labels with a much lower price tag for point cloud domain. We addressed the question of what the best way is to provide high accuracy annotation of point cloud data? We approached this question from three different viewpoints, (1) by contributing to the state of the art methodology for 2D image segmentation in generating semantic maps based on (2D projected) point cloud data, (2) by employing deep learning modeling techniques specifically developed for raw point cloud data handling directly, and (3) by combining deep learning-based modeling and minimal human-perception in our proposed semi-automatic annotation tool capable of generating fast and accurate point cloud labels, called SAnE: Smart Annotation and Evaluation tools. The SAnE annotation tool was a join product between Carnegie Mellon University (CMU) in the USA and Norwegian University of Life Sciences (NMBU) in Norway.
One of the most notable results from our works is that we show that our approach speeds up the annotation process by a factor of 4.36 while achieving Intersection over Union (IoU) agreements of 84.26%, +22.77% higher than the baseline annotation accuracies. Experimenting with Amazon Mechanical Turk crowdsourcing services, the crowdsourcing workers, by using the full feature of SAnE, can provide point cloud labels with mean-IoU accuracy of 79.57%, while by using the baseline annotation tool the accuracy drop to only 61.50%. It shows that our annotation tool is capable of delivering fast and accurate annotation labels for large-scale datasets with a much lower price tag.